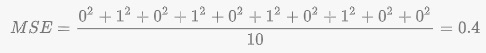Google:Descending into ML: Linear Regression(線形回帰)の和訳
GoogleのDescending into MLの和訳です。
元記事
Descending into ML: Linear Regression
機械学習へ降りる:線形回帰
コオロギ(昆虫種)は、涼しい日よりも暑い日に多く鳴くことが長く知られています。
約数十年間、専門家とアマチュアの科学者は、1分あたりの鳴き声と気温のカタログデータを持っています。
誕生日プレゼントとして、おばさんはコオロギのデータベースをくれて、この関係性の予測を学習するように頼みました。
このデータを使って、この関係性を調査したいです。
最初に、プロットすることでデータを調べます。
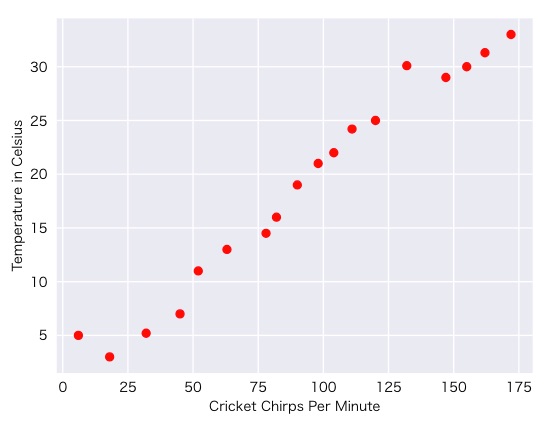
図1:摂氏の気温とコオロギの1分あたりの鳴き声の関係
予測としては、気温と共に鳴き声が増加していることを表しています。鳴き声と気温の間の関係は線形でしょうか?
はい、あなたはこの関係を以下のような1つの直線にすることができます。
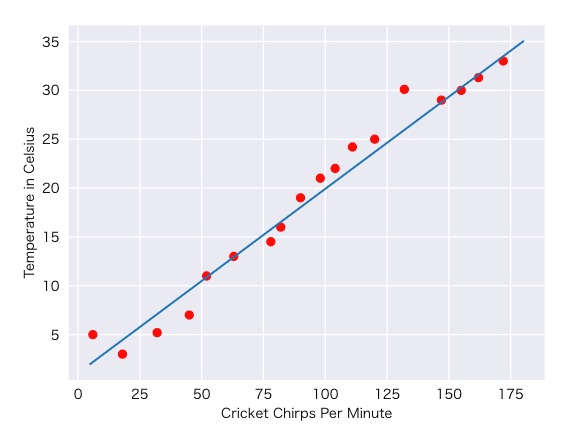
図2:線形の関係
はい、ラインは全ての点を通ってはいませんが、線は明らかに鳴く回数と気温の関係性を現しています。
線を等式を使って表すと、以下のように関係性を書くことができます。
y = mx + b
ここで
・ yは予測しようとする摂氏の温度です。
・ mは線の勾配です。
・ xは分あたりの鳴く回数で、入力値です。
・ bは、yの切片です。
機械学習の慣例として、少し違うように以下のように書きます。
y’ = b + w1x1
ここで
・ y’は予測するラベルです。(望まれる出力)
・ bはバイアス(yの切片)で、w0を参照します。
・ w1は特徴1の重みです。重みは、伝統的な線形の等式の勾配mと同じ概念です。
・ x1は特徴です。(明示的な入力)
新しい分あたりの鳴く回数x1の温度y’を予測するために、ただx1の値をモデルに置換します。
このモデルが単一の特徴を使うと課程して、より洗練されたモデルは複数の特徴を頼りにし、それぞれは別の重み(w1、w2、etc…)を持ちます。
例として、このモデルは以下のような3つの特徴を頼りにします。
y’ = b + w1x1 + w2x2 + w3x3
訓練と損失
モデルを訓練するのは、単純な意味としては、ラベルの例から全ての重さとバイアスのための良い値を学習(決定)することを意味しています。
学習の監督として、機械学習アルゴリズムは、多くの例を調査することによってモデルを構築し、損失を最小化するモデルを発見することを試みます。このプロセスはempirical risk minimization(経験損失最小化)と呼ばれます。
損失は悪い予測に対してのペナルティです。それは、損失は、単一の例のモデルにおける予測がどれだけ悪いかを指し示す数です。
もしモデルの予測が完全だったとすれば、損失は0になります。
それ以外では、損失はより大きくなります。
モデルを訓練することのゴールは、全ての例においての平均の少ない損失を持つ重さとバイアスを見つけることです。
例として、図3では左に高い損失のモデルを、右に低い損失のモデルを示します。
図では以下のことを示しています。
・ 赤の矢印は、損失を表しています。
・ 青の線は予測を表しています。
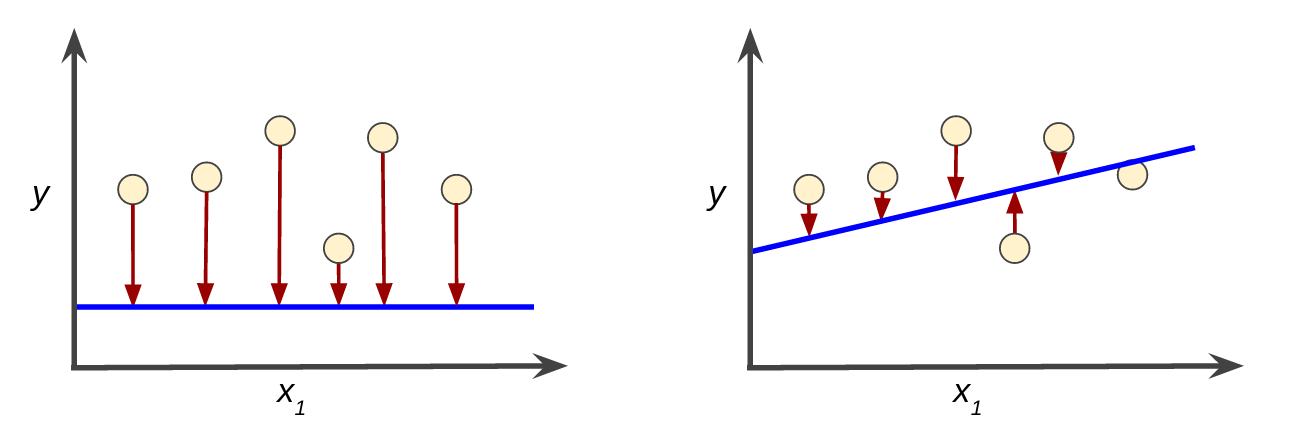
“図3:左が高い損失のモデルで、右が低い損失のモデル
左図の赤の矢印は右図に比べてより長いことに注意してください。
明らかに、右図の青い線は左図に比べてより良い予測になります。
意味のあるやり方における個々の損失の集合させる数学的な関数-損失関数-を作ることできないかどうか不思議に思うかもしれません。
二乗損失(squared loss):有名な損失関数
ここで私達が検討するであろう線形回帰モデルは二乗損失(L2損失としても知られる)と呼ばれる損失関数を使用しています。
単一の例に対する二乗損失の例は以下のようになります:
= ラベルと予測の差分の二乗
= ( observation -prediction(x))2
= ( y – y’)2
平均二乗誤差-Mean scuqre error(MSE)は全データセットにおける例の平均の二乗の損失です。
MSEを計算するには、個々の例の損失の二乗を総和し、例の個数で割ります。
MSE = 1/N Σ (y – prediction(x))2
ここの
・ (x,y)は以下の例です
・ x はモデルが予測を生成するのに使う特徴のセット(例として、1分あたりのコオロギの鳴き声、年齢、性別)です。
・ y は例のラベル(例として、気温)です。
・ 予測xは、特徴セットxの組み合わせにおける重みとバイアスの関数です。
・ Dは(x,y)における多くのラベル付けされた例を含むデータです。
・ NはDにおけるいくつかの例です。
MSEはマシンラーニングにおいて頻繁に使われますが、唯一の実用的な損失関数でもなければ、全ての状況における最善の関数でもありません。
理解度のチェック
平均二乗誤差 (Mean Squared Error)
以下の2つのプロットを考えます。
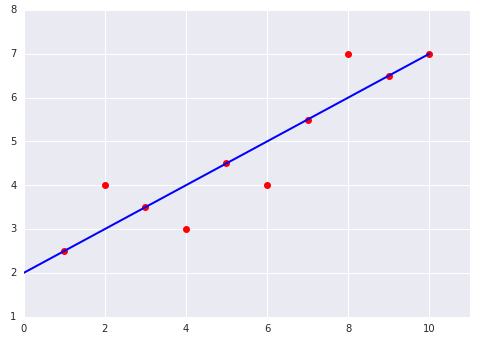
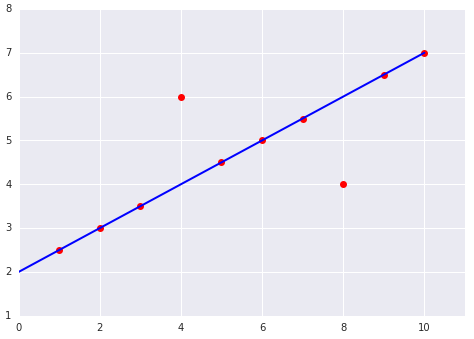
以下の選択肢を考えてみてください。
どちらの前述のデータセットが高い平均二乗誤差(MSE)でしょうか?
・ 下のデータセットです。
◯ 正解です。
8つの線形の例はトータルで損失が0です。
しかしながら、2つの点は線を外せていますが、両方の点は上図の外れ値の点の2倍です。
二乗損失はそれらの差分を増幅し、2つのオフセットは1つのオフセットよりも4倍大きい損失を招きます。
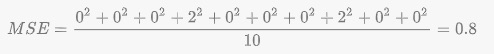
・ 上のデータセットです。
☓ 不正解です。
6つの線上の例は、トータルの損失が0です。
4つの線上の例は線からそれほど離れていませんが、それらのオフセットの2乗は低い値を生み出します。